
FakeApp换脸软件是一款国外非常火的ai智能自动视频换脸软件。这款软件利用了deepfake的AI技术进行视频换脸。贝莱视频换脸需要一定的技术,但是这款FakeApp换脸软件的出现,将技术的门槛降低了不少,让很多的用户都可以利他来制作各种搞笑的换脸视频。FakeApp软件通过ai人工智能技术,软件会自动识别图片或者视频中的人脸数据,将不同的任务脸部进行快速替换。不仅能换脸,还可以修改脸型,因此玩起来了会有意想不到的效果哦。如果还还在导出找好用的换脸软件,推荐你可以试用这款。软件使用方法简单,无需专业的知识就可以掌握基础的技术了,感兴趣的来试试吧。
2.提供了多样化的数据采集,轻松观看培训过的人工智能季度。
3.能自动分割、转换和拼接视频,让你的视频中的人脸转换更快。
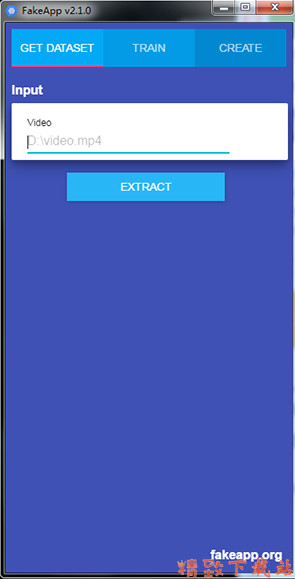
先创建一个文件夹fake,将素材视频存放进去
咱们姑且用A和B来区分这两个小姐姐好了,按照FakeApp的提示,将素材路径填入,点击EXTRACT,接下来无需任何操作,等程序跑完就行了。你会看到fake文件夹中多出了一个dataset-A的目录,这便是我们待会儿训练模型时需要的数据集了。A的训练集生成后,重复这一步骤,生成B的训练集。至此,咱们第一步结束了。
2.第二步,训练模型
在这一步开始前,你需要在fake文件中创建一个model目录,这里会存放模型文件。和之前一样,依次填入文件夹路径,下面的参数无需修改,使用默认配置即可。点击TRAIN,等待程序初始化后,会弹出一个预览框,这时,你几乎可以高枕无忧了。刚开始你会发现预览框最右侧的一列会非常模糊,不要紧,模型才刚开始训练。Loss A和Loss B代表模型的差异值,咱们无需关注数值产生的原理,你只需要知道,两者之差越小,说明模型训练的越好。
训练模型是一个很耗时间的活儿,以我为例,每个数据集各350张左右的面部图像,训练了大概13个小时,差异值稳定在了0.1%左右。如果你想要更好的效果,建议每个数据集不低于500张,至于如何确定数据集的大小,可以看上面的示例图A,图中的360代表dataset-A的数据量。
值得一提的是,训练进度会被实时保存下来,也就是说你可以随时暂停训练,在预览窗口中,输入英文小写字母q即可保存退出,下次想要继续训练的话,打开FakeApp再点击TRAIN即可。
3.第三步,开始操作
在model中填入我们先前训练好的模型路径,Video则填入你想要替换的视频路径,依旧是傻瓜式,点击CREATE,稍安勿躁,让GPU飞一会儿~程序跑完后,你应该就能在fake文件中看到生成的swap.mp4文件了,让我们通过视频截图,看看效果如何。
提取码
yl5n软件特色
1.FakeApp可以几分钟的时间就可以采集数千张的图片和视频。2.提供了多样化的数据采集,轻松观看培训过的人工智能季度。
3.能自动分割、转换和拼接视频,让你的视频中的人脸转换更快。
使用教程
1.第一步,生成数据集先创建一个文件夹fake,将素材视频存放进去
咱们姑且用A和B来区分这两个小姐姐好了,按照FakeApp的提示,将素材路径填入,点击EXTRACT,接下来无需任何操作,等程序跑完就行了。你会看到fake文件夹中多出了一个dataset-A的目录,这便是我们待会儿训练模型时需要的数据集了。A的训练集生成后,重复这一步骤,生成B的训练集。至此,咱们第一步结束了。
2.第二步,训练模型
在这一步开始前,你需要在fake文件中创建一个model目录,这里会存放模型文件。和之前一样,依次填入文件夹路径,下面的参数无需修改,使用默认配置即可。点击TRAIN,等待程序初始化后,会弹出一个预览框,这时,你几乎可以高枕无忧了。刚开始你会发现预览框最右侧的一列会非常模糊,不要紧,模型才刚开始训练。Loss A和Loss B代表模型的差异值,咱们无需关注数值产生的原理,你只需要知道,两者之差越小,说明模型训练的越好。
训练模型是一个很耗时间的活儿,以我为例,每个数据集各350张左右的面部图像,训练了大概13个小时,差异值稳定在了0.1%左右。如果你想要更好的效果,建议每个数据集不低于500张,至于如何确定数据集的大小,可以看上面的示例图A,图中的360代表dataset-A的数据量。
值得一提的是,训练进度会被实时保存下来,也就是说你可以随时暂停训练,在预览窗口中,输入英文小写字母q即可保存退出,下次想要继续训练的话,打开FakeApp再点击TRAIN即可。
3.第三步,开始操作
在model中填入我们先前训练好的模型路径,Video则填入你想要替换的视频路径,依旧是傻瓜式,点击CREATE,稍安勿躁,让GPU飞一会儿~程序跑完后,你应该就能在fake文件中看到生成的swap.mp4文件了,让我们通过视频截图,看看效果如何。





























